|
|
|
|---|---|
An Article on contemporary of Organizational Intelligence 
|
|
|
|
|---|---|
An Article on contemporary of Organizational Intelligence
|

Introduction to this Article |
This organization may be educational, scientific, administrative (such as government departments) or business oriented. The common element this theory will assume will be the computer systems software employed to conduct the record keeping of the organization, and the mandatory presence of database system software.
We firstly introduce a broad definition of computerized
organizational intelligence to be
at least the sum of the
data plus the sum of the application code associated with
this data.
The collective of computerised code (at all levels) developed over a period of time by this organisation to assist the running of its practice, is thus defined as part of its computerized organizational intelligence. This will include every single element of computer code utilised in the day-to-day, the week-to-week, the month-to-month and cycle-to-cycle processes of that organization.
An organization's (computerized) intelligence may be defined to be contained within the dynamics of its three separate yet highly interconnected computer software systems environments, shown at FIG 1:
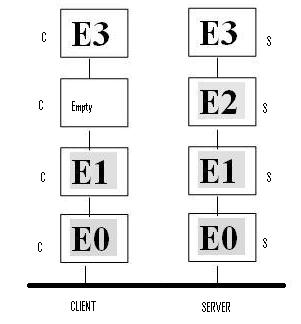
|
In the source code of each of the component application objects there rests an intelligence by design of the author of the code. This quantum of intelligence is an intelligence with respect to the organisation itself, and its routine processes.
For example, a daily report may summarise yesterdays problem incidents. This is one small quanta in an oceanic consideration. Mechanisms by which the application system suite of components is coordinated and managed also need to be included in this sum, and these contribute to an emergent sum greater than the parts.
In the physical database file containing the organization's data is the balance of computerized Organizational Intelligence. As the RDBMS environment has become enrichened with services and utilities over the decades, it would be fair to comment that more and more organizations have more and more Organizational Intelligence bound up in this file each year of its service.
Like yang and ying,
the code and data
are almost inseparable,
and almost equally and totally useless
without the other.
|
The currently promulgated Database Systems theory relies exclusively upon the frame of reference of the data. Due to historical associations at its inception 30 years ago, it assumes the dichotomy of the data and the application, as it was 30 years ago. This basic axiomatic foundation of current theory is no longer applicable to technological reality.
A separate article entitled Incompleteness of the Relational Model describes in a straightforward manner how the current paradigm can be seen to be incomplete, providing concrete example of its failure to address stored procedure object data within the database systems environment.
A new database systems theory needs to be put forward for discussion which will enhance the context of the current database systems theory, and the Relational Model of the data, and place them in a dynamic framework that that is capable of addressing the notion of application software, and thus, in the end, the notions of applications, process, workflow, and organizational intelligence
An outline of such a theory follows, in an informal manner, using the method of presenting common-sense hypotheses.
|
|
From hypothesis 1 and 2, equation 1 follows that the sum dynamic total of organizational intelligence bound within an organization’s computer systems and at the disposal for use, is at least equal to the sum dynamic total of organizational intelligence bound with each of the operational computer systems software environments E1, E2, E3 (See FIG 1). This is represented informally in Equation 1 below:
|
The above theorem (Eq.1), where Sum(OI(E1)) << Sum(OI(E2)) + Sum(OI(E3)), can thereby be simplified to two terms in equation 2:
This depicts the prior art information technology management solution (2004) for the storage or binding or development of organizational intelligence. It is distributed across two software system environments, both reliant upon a third. This has been the case for at least two decades.
Clearly, it must be recognised that organizational intelligence is presently being stored in a union and conjunction (of software systems).
|
DBMS and RDBMS products became necessary because the data structures so created above were soon identified operationally to be extremely volatile. Hardware was primitive, E0 memory was expensive and miniscule. The open file for input and output approach had severe limitations with large rows and large concurrent usage. Data access required greater speed and precision.
Relational Systems released the Oracle RDBMS product in 1979, with IBM following suit (DB2) soon after, and Microsoft (SQL Server) in 1989. Other mainframe and minicomputer vendors ( e.g: Wang Laboratories) maintained their own DBMS.
Today E2 is furnished with a complete range of operational, administrative and management services, including backups, scheduling, import and export of data, etc. A program development environment also exists internal to the RDBMS called Structured Query Language (SQL), by which the database can be manipulated.
Such native SQL code can be stored as operational and application level components. These are known as RDBMS stored procedures.
Application system software (E3) today now deals directly with the RDBMS (E2) and has become increasingly disassociated with the operating system software (E1). Many E3 products are now packaged independent of E1.
There also appears to be a slow but definite migration of organizational intelligence from the environment E3 to the environment E2 in recent times, as a direct consequence of services and efficiencies existent within E2.
When the component objects of application systems software are listed, it is becoming common to find more and more use of stored procedure objects within E2. What might be the systematic endpoint of such a migration of OI?
|
However, the heaviest redundancies are identifiable in the coordination tasks related to the administration of the distributed suite.
Such inefficiencies are highlighted by the expense and activity of all development and change management cycles associated with the methodologies of contemporary application system software.
The cost aspect is often critical to organizations, whether business, educational or government. It might be thus said that OI is being purchased at a price that is not realistic.
|
Consider a general computer system as earlier defined (equation 3) where the components of an application system, distributed through client-server environments E2S, E3S and E3C, (Refer to the earlier diagram) are defined by the three extendable series:
E3s = S1, S2, S3, …, Sn (S = server side application components)
E3c = C1, C2, C3, …, Cn (C = client side application components)
|
CT2 between Cn (C1, C2, C3, …, Cn) and Pn (P1,P2,P3,…,Pn)
ie: between the client application suite and RDBMS stored procedure componentry.
CT3 between Sn (S1, S2, S3, …, Sn) and Pn (P1,P2,P3,…,Pn)
ie: between the server application suite and RDBMS stored procedure objects
CT4 between Cn (C1, C2, C3, …, Cn) and the database.
ie: between the client application suite and database schema
CT5 between Sn (S1, S2, S3, …, Sn) and the database.
ie: between the server application suite and database schema
CT6 between Pn (P1, P2, P3, …, Pn) and the database.
ie: between the RDBMS stored procedure objects and database schema
The size of these six coordination tasks of course is proportional to the number of component objects being coordinated. When the size is large, as is the case with most comprehensive applications, then the coordination tasks in change management are excessively highly detailed.
Certainly, there have of course evolved automation tasks and functionality products to assist in these administrative and management tasks. But these tasks require establishment and continual calibration, and only serve to hide the undercurrent of thrashing about in re-definitions of OI.
All the above considerations are totally independent of the additional physical management tasks involved in the distribution of the components from the development phase, to the implementation phase. The executable objects C1, C2, C3, …, Cn are to be physically loaded on all client machines, whereas the objects S1, S2, S3, …, Sn need go to the server machine(s).
The objects P1, P2, P3, …, Pn are stored procedures which need to be imported to the RDBMS on the server(s), if they are not already located there.
There exists OI in the sum of all these components and, as indicated above, OI is identifiable within tasks reserved for the coordination of the suite. The ongoing maintenance cost associated with the components is normally small per component. However it is common practice to spread the cost associated with coordination of the components across the components. As a consequence, what is going on behind the scenes is often hidden.
|
The comprehensive character of an application system is determined in part by the number of separate elements of information it addresses. Each of the elements must be capable of being maintained in some fashion, and it is usual that there will exist some user interface to every data element.
As a consequence of this, the functionality of a database application system might in theory be split into two parts. On the one hand, there is the user and the user interface receiving and entering data elements, and on the other hand there is the database, sending and recording the data elements respectively.
It is quite common that a large percentage of the components of an application suite are simply user interfaces and views to the extensive landscape of a database schema. A database schema is simply the detailed specifications of each column, in each database table in the database.
If the organizational intelligence inherent in the schema of the data to be presented via a user interface has already been once defined (E2s) therein, why need it be redefined again at the user interface (E3c) within the code?
As an example, a component of a suite may be responsible for the data entry of names and addresses. The fields on this data entry interface screen must match the fields in the database. The OI in this interface thus has a duplicate set of data definitions for names and addresses.
The source and original definitions of these fields are defined with the OI in the database schema. The OI in the source code of the application on the client machine (or application server) is a redundancy.
Every user interface component within an application system software suite contains normally hard-coded re-definitions of fields for display to the user, obviously already defined in the source database schema. Every user interface in standard methodology application software today represents a redundancy in organizational intelligence.
The redundancy is represented by either the physical redefinition of the relevant schema of the data (related to that interface) within the E3 code constituting the E3 interface, or a physical I/O call from the E3 code to the database to get that schema.
|
We work-around this seeming paradox, by engineering a generic user-interface purposefully devoid of any organizational intelligence. That is, the user-interface is a generic portal to the RDBMS services and environment and contains no reference to application software layer behaviour.
The resultant tool has been called RDBMS portal software, and remains effectively totally unchanged from installation to installation. The tool is the user-interface between the organizational user and the RDBMS, and is totally independent of the organization, and the organization's application software layer.
We make mention of this tool, in this draft of a theory of organizational intelligence, because it was the catalyst for the theory. For further information on RDBMS portal software technology, and its unique methodology see the background articles on LittleSteps: RDBMS portal software elsewhere at this site.
|
We have introduced a formalism of the notion of the change management of organizational intelligence in the identification of six separate categories of general coordination tasks (CT1 to CT6 above), with respect to the database system in general, and specifically a dynamic schema definition.
These two formalisms do not yet exist within cohesive database systems theory as far as I am aware, to the extent that they are modelled in the same system model as the data itself. My belief is, that in the long term all such mandatory and logical processes associated with the organization's database system, and its change management, need to be modelled by theory.
Where does the current theory fit in? This is an interesting exercise.
Firstly we need to define the
scope of the current theory.
|
Operators are provided for operating on rows in tables
and those operators directly support the process
of inferring additional true propositions from the given ones. .[trim].
A data model is an abstract, self-contained, logical definition
of the objects, operators, and so forth,
that together constitute the abstract machine
with which the users interact.
The objects allow us to model the structure of data.
The operators allow us to model its behaviour.
-- C.J.Date: "Database Systems"; Introduction, p14
Central to any theory of organizational intelligence is not just the data, but the application processes which surround the data, the work-flow queues by which the data is approached. Also implicated in any theory of organizational intelligence is the theory of the management of change, with respect to the components of all other elements of the theory.
The Relational Model is very successful at what it does and was essentially responsible for the evolution of the RDBMS out of the competing DBMS products available in the 1960's and 1970's.
Standing alone, the Relational Model of the data is inadequate to comprehend the notion of organizational intelligence, and its change management, in entirety.
|
The Relational Model of the Data needs to be placed into the perspective of this new vantage point, which has essentially evolved technologically out of the RDBMS software that the relational model inspired.
Automation of process is a fundamental concept in the theory of organizational intelligence, which regards both the processes and the data within the relational database systems of today.
|
Implicit in all prior art methodology are massive redundancies associated with the redefinition of OI in both systems software environments, and the high-level coordination of these redefinitions.
|
The great One Thousand Tasks appear if time is taken to list them and it may be determined that there are many categories of these that are amenable to theoretical generalization.
My personal view is that organizational intelligence should be engineered to run totally within the RDBMS environment as described in the above reference to the LittleSteps RDBMS portal software.
Where the complete entirety of all database application system development and change management processes are SQL tasks, wholly defined within one unified (RDBMS software) environment, there will be great efficiencies of operation, administration and management.
Under such a methodology, complete application system software suites are scriptable, given the underlying database schema, and are able to be packaged and delivered as database files.
Moreover, under this methodology, all organizations would not have any change management considerations in the client environment as all organizational intelligence would be not only centralised on the RDBMS server, but would be unified in its definition within database systems software.
PRF Brown
Winluck Pty Ltd.
IT Managers & Engineers
Falls Creek, Australia
http://www.mountainman.com.au/software